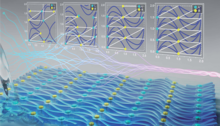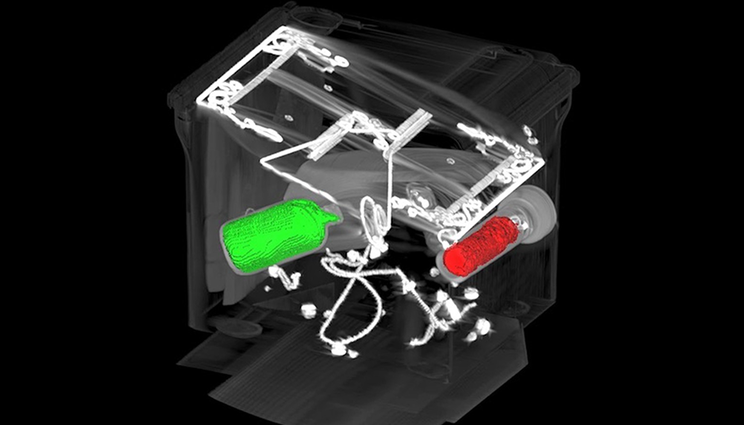
3D segmentation result obtained using the DOLCE CT reconstruction technique. To a set of 274 limited-angle (θmax=90°) CT images reconstructed using DOLCE, researchers applied an automatic segmentation method to identify boundaries of high-intensity objects.
(Download Image)For better CT images, new deep learning tool helps fill in the blanks
At a hospital, an airport, or even an assembly line, computed tomography (CT) allows us to investigate the otherwise inaccessible interiors of objects without laying a finger on them. To perform CT, x-rays first shine through an object, interacting with the different materials and structures inside. Then, the x-rays emerge on the other side, casting a projection of their interactions onto a detector. By repeating the process over the course of a 180° arc, computer algorithms can piece together the many angle-dependent projections to resolve and reconstruct the object’s interior in three dimensions.
Dozens of techniques exist to mathematically reconstruct an object in 3D, but unlike in theoretical research where high-fidelity data may be plentiful, real-world implementations of CT reconstruction encounter several obstacles that can produce image artifacts and degrade reconstruction results. LLNL researchers collaborated with the Computational Imaging Group at Washington University in St. Louis to devise a state-of-the-art, machine learning (ML)–based reconstruction tool for when high-quality CT data is in limited supply.

Of particular interest to the team are cases of severe angle constraints against which typical reconstruction algorithms are no match. LLNL computer scientist and principal investigator Hyojin Kim explains, “There are challenging CT scenarios in which a system is unable to sweep out a full angular range (typically 180°–360°), meaning there are entire regions where we have no data whatsoever to work with. These limitations occur in some fixed-gantry CT setups, certain border and airport security systems, and when the scanned objects are thin and dense such as with printed circuit boards.” In some cases, data can only be gathered from as little as a 60° range. So far, limited-angle CT (LACT) algorithms have struggled to overcome these lapses in data, posing challenges for CT applications where obtaining high-accuracy reconstructions is necessary yet often physically and computationally impractical.
“All reconstruction methods have to make certain assumptions to operate, but with LACT, it’s like we’re being asked to determine what’s around the corner without being allowed to look,” says Rushil Anirudh, an LLNL ML researcher contributing to the project. While at first the task of interpreting nonexistent data would seem impossible, he explains the group’s new ML tool offers a way to predictively “fill in” missing details from scans and achieve high-resolution 3D reconstructions with crisp object edges.

As detailed in a recent paper—accepted to the 2023 International Conference on Computer Vision (ICCV), one of the most prestigious global computer vision events—the team devised a deep learning–based framework for predicting the absent CT data and enhancing 3D reconstruction. “Deep neural networks can act as good priors for predicting missing details,” says Anirudh. “The premise is that after showing the model a sufficient number of images of cats, for example, if you then present it with just the head of the cat, it will be able to predict what the rest of the body looks like.” The predictions prove remarkably similar to reality, or ground truth. The team’s Diffusion Probabilistic Limited-Angle CT Reconstruction (DOLCE) model was exhaustively trained on hundreds of thousands of medical and airport security x-rays to learn how to incrementally refine these images and restore missing data through the deep learning process of diffusion.
Anirudh says to appreciate diffusion as a generative process, imagine a drop of dye added to water. The dye naturally spreads throughout the fluid, transitioning from a deterministic state to one less predictable. This process is akin to adding Gaussian noise to a training image. DOLCE’s diffusion process to learn image reconstruction winds back the clock. The model learns to iteratively de-noise a fuzzy image to arrive at the most probable starting point—that is, the initial drop of dye—which is ideally equivalent to the ground truth CT image.

Kim explains how DOLCE addresses another major challenge facing LACT reconstruction. “In the diffusion framework, each time we de-noise an image, we forward-project (generate a reconstruction) to compare with the ground truth and ensure data consistency. However, we don’t start with clear images, so there is no real ground truth to compare with.” Instead, DOLCE constantly checks the reconstruction solution and adjusts it for consistency and adherence to real-life, physical constraints (i.e., the original x-ray projection data). DOLCE alternates between the de-noising step and the data consistency check until complete, resulting in higher quality 3D reconstructions than those produced by other models, even though it was only trained on 2D CT images. This process of iterative refinement was achievable thanks to another technological advancement at the Laboratory. Kim’s open-source software library, Livermore AI Projector (LEAP), enables differentiable forward- and back-projection and smoothly integrates with Python to facilitate the training process.
The research team found that a diffusion approach offered greater scalability than other deep learning methods, such as generative adversarial networks. As a result, DOLCE can handle large data distributions to tackle CT reconstruction tasks outside the initial medical and security imagery it trained on. It also can quantify the uncertainty associated with a particular reconstruction. This combination of capabilities makes DOLCE ideal for other LACT circumstances such as imaging circuit boards, which are normally too wide along one plane to be accurately scanned at all angles. It is also a powerful tool for capturing certain high-density materials—often the target of security scans—that otherwise cause imaging artifacts, impacting reconstruction efforts. By reporting the level of confidence that the reconstruction is correct, DOLCE is extensible to an array of imaging challenges of research and security concerns.
Further contributors from Livermore include Stewart He, Jayaraman Thiagarajan, and Aditya Mohan. Jiaming Liu (previously a summer intern at Livermore) and Ulugbek Kamilov are researchers at Washington University in St. Louis.